FAIR Principles In Research Data Management
-
FAIR Principles In Research Data Management
-
What Are FAIR Principles
Horizon Europe projects follow an open science approach that relies heavily on the adoption of the FAIR principles for research data management. Applying these principles does not mean that all data must be made publicly available, but rather that they should be made as easy as possible to find, access, interoperate and reuse — whether by other researchers, professionals, or even yourself in the future.
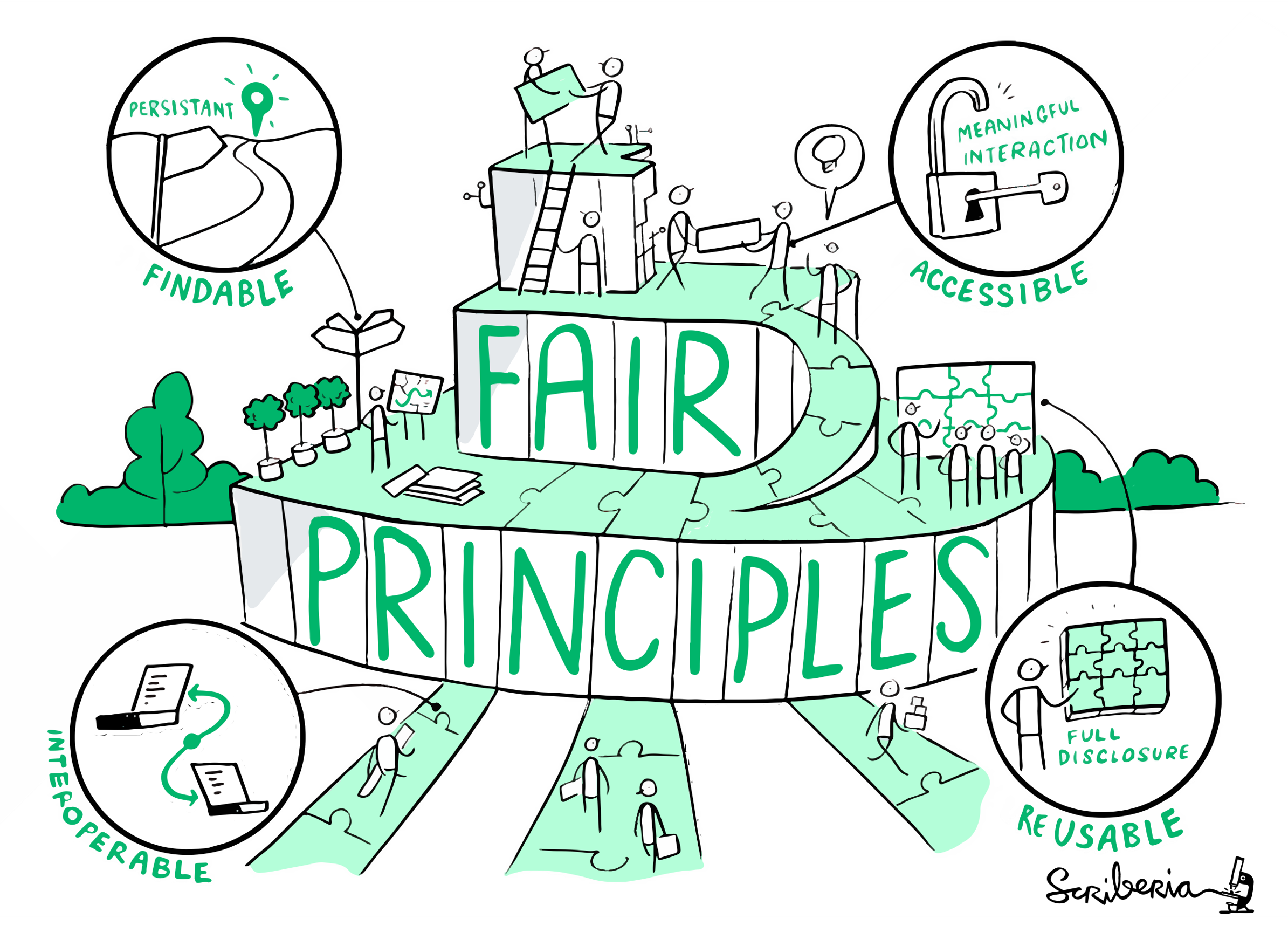
Source: The Turing Way project illustration by Scriberia. Used under a CC-BY 4.0 licence.
The term FAIR is an acronym:
- Findable: Data should be easy to discover for both humans and machines. This means using trusted repositories, assigning persistent identifiers (such as DOIs), and providing rich metadata so that others can search for and identify your datasets.
- Accessible: Once found, data should be retrievable using clear and standardised methods. Accessibility does not necessarily mean open to everyone—some data may require authentication or request procedures—but the conditions of access must be transparent.
- Interoperable: Data should use standard formats, vocabularies, and metadata so that they can be combined with other datasets and used across different tools, platforms, or disciplines. Interoperability is essential for multidisciplinary research and long-term usability.
- Reusable: Data should be well-documented, with clear licences that specify how they can be used. Reusability requires accuracy, provenance information (who created the data, when, how), and compliance with ethical and legal standards.
Applying the FAIR principles increases the potential impact of your data: they will be easier to discover, to cite and to integrate into new studies. It also helps save time internally, by simplifying daily data management, future reuse, or data transfer to collaborators. Above all, it provides a concrete response to growing expectations from funders, institutions and journals, which increasingly require that research data be well-managed, accessible and sustainable.désormais des données mieux gérées, plus accessibles, et plus durables.
Making your data FAIR relies mainly on good documentation practices. This includes giving files coherent names, writing a clear README file, choosing open rather than proprietary formats, describing datasets in the metadata provided at the time of deposit, selecting an explicit licence that permits or regulates reuse, and depositing your data in a trusted repository that assigns a persistent identifier.
-
FAIR vs. Open Data
FAIR does not mean “open by default.” Open data is data that can be freely used, re-used and redistributed by anyone - subject only, at most, to the requirement to attribute and sharealike. Open data is machine-actionable (or: machine-readable) data with an open license. Thanks to the license, the data is freely available to everyone. Open data can be, for example, population data, map data or, for example, real-time data on bus locations. The Open Data Handbook summarizes the most important:
- Availability and Access: the data must be available as a whole and at no more than a reasonable reproduction cost, preferably by downloading over the internet. The data must also be available in a convenient and modifiable form.
- Re-use and Redistribution: the data must be provided under terms that permit re-use and redistribution including the intermixing with other datasets.
- Universal Participation: everyone must be able to use, re-use and redistribute - there should be no discrimination against fields of endeavour or against persons or groups. For example, ‘non-commercial’ restrictions that would prevent ‘commercial’ use, or restrictions of use for certain purposes (e.g. only in education), are not allowed.
When we talk about FAIR data, we mean data that complies with the FAIR Principles, whereas the concept of open data is based on the democratic idea to provide data to anybody interested - without any barrier, restriction, or payment. In the context of FAIR, data should be understood as a broad concept that can refer to data, metadata, software, code, models and other documentation that makes research reproducible. FAIR does not mean that all data should be made openly available; only the discovery metadata needs to be openly available. The data can be either open or available with restrictions if necessary. This should be stated in the terms of use in the administrative discovery metadata and include a machine actionable license.
✅ An example of data that are OPEN but not FAIR would be a researcher making several files available on a personal website, with names such as “Data_final_v3.xls” or “Protocol.docx”. These files are freely accessible and therefore “open”, but they are not properly referenced (no DOI), rely on proprietary and poorly sustainable formats, and lack metadata and a clear licence. As a result, although the data are openly available, they are difficult to find, understand, and reuse.
✅ An example of data that are FAIR but not OPEN is commonly found in medical research. Anonymised imaging data may be deposited in a certified repository, with a DOI, rich metadata, open and interoperable formats such as DICOM or CSV, and a licence specifying the conditions for reuse. These datasets are interoperable with other resources and well documented, but access is restricted to authorised researchers in order to protect patient privacy. The data therefore fully comply with the FAIR principles, even though they are not openly accessible to everyone.
-
Additional Resources :
-
[Link] GO FAIR | FAIR Principles
-
Self-Assessment Quiz
-
[Self-assessment quiz] FAIR Principles
-