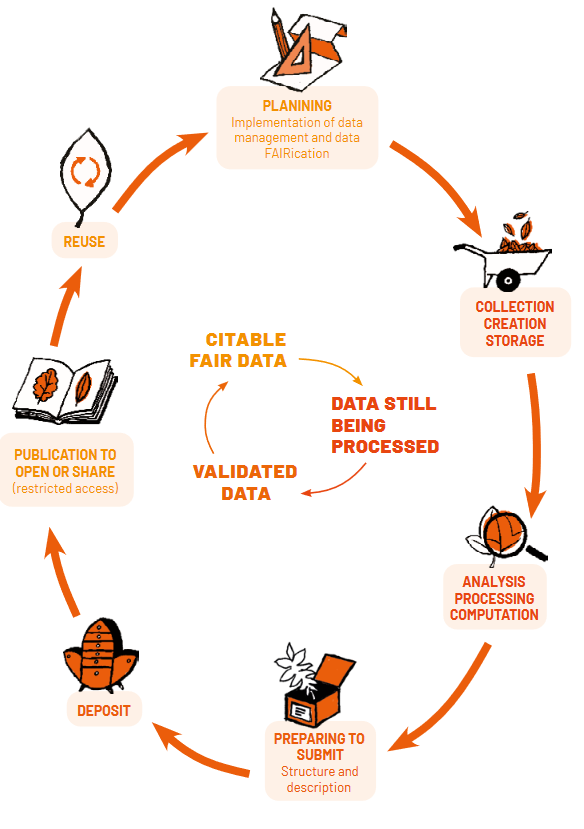
Research Data Lifecycle
-
Research Data Lifecycle
-
Planning Phase
During the planning phase, not only the design of the research should be planned but also the management of the data. By preparing a data management plan, it is important to consider aspects of data management before the actual work starts. In the planning phase the researcher gets an impression of what kind of datasets will be generated, has a look into useful existing data sources and agrees on how to share data during and after the project, documents data collection and processing, names files, etc.
-
Using and Reusing Data
Before starting to collect new material, it is often worthwhile to check whether suitable datasets already exist. Reusing data can save time and resources, avoid unnecessary duplication of effort, and create opportunities for comparative or interdisciplinary research. For doctoral projects, it also offers a valuable way to gain experience in exploring, assessing, and working with external datasets.
How to find existing data
To locate relevant datasets, you can use:
- Disciplinary repositories listed in registries such as re3data.org which often provide community-validated data.
- Search engines designed for research data, such as Google Dataset Search, BASE, B2FIND, or the DataCite Metadata Search.
Repositories and search services usually provide metadata—descriptions of the dataset that include its content, origin, and conditions of use. The richer and more precise the metadata, the easier it is to assess whether the dataset is relevant for your research.
However, finding a dataset is only the first step. Before reusing it, you need to make sure that it is sufficiently documented to understand how it was created and under what conditions it can be used. You must also check whether it fits the scope of your research question and whether it is of adequate quality and reliability according to disciplinary standards. When in doubt, it is often a good idea to contact the original producers of the dataset to confirm details or obtain clarification.
Respecting copyright and terms of use is another crucial aspect. Not all data available online can be reused freely. You must check the licence associated with the dataset to know whether you are allowed to download it, copy it, redistribute it, or use it in a commercial or non-commercial context. In most cases, attribution and proper citation are mandatory. Particular caution is needed with social media content: before collecting posts, images, or messages, always verify whether the platform’s terms of service allow downloading and saving for research purposes.
Finally, legal and ethical aspects must be considered. If the dataset contains personal, sensitive, or confidential information, you need to comply with data protection regulations such as GDPR and respect ethical principles. This means ensuring that reuse is legally authorised and that the rights and privacy of participants are preserved.
💡 In short, reusing data is both efficient and responsible, but it requires careful evaluation of documentation, quality, licences, and ethical or legal conditions. When these aspects are properly addressed, existing datasets can significantly enrich a PhD project and reinforce its scientific value.
-
Data collection
In the collecting phase, new datasets will be generated and existing ones found that can be re-used for the research´s purpose. At best, third-party data that is free for reuse (free license). In other cases, payment may be required for the utilization of existing data. It is always to be remembered to check and document the source of the data and ensure the capture of all other relevant metadata (metadata means detailed information that describes and provides context for research data).
The way research data are collected depends strongly on the discipline and research design. Data may come from experiments, surveys, interviews, observations, instruments, sensors, or be retrieved from external sources such as repositories or archives. From the outset, it is essential to plan collection methods carefully and to document them clearly, so that the data can be understood, reused, and validated later. Good practices include:
- Creating and keeping a copy of the raw/original data, and working on duplicates to avoid accidental loss.
- Recording the source of each dataset, including references for external data.
- Ensuring that consent and ethical requirements are met if personal or sensitive information is involved.
- Capturing contextual information (metadata) during collection, such as date, location, instruments used, or protocols followed.
👉 High-quality, consistent data are the foundation of trustworthy research. Steps to ensure this include:
Step 1. Preserving the integrity of files when exporting from one system or format to another.
Step 2. Maintaining multiple backups and versions of datasets, so that earlier states can be restored if necessary.
Step 3. Checking transcriptions or codings (e.g. of interviews) for accuracy; if the data are sensitive, verification must be done within the project team.
Step 4. Using consistent protocols (survey questionnaires, interview guides, measurement methods).
Step 5. Regularly calibrating instruments and validating measurement procedures.
Step 6. Verifying that digitised data (e.g. scanned documents, converted images) correspond faithfully to the originals.
-
Processing phase
During the processing phase, data is worked on, checked, validated, and cleaned, with anonymization carried out whenever required. It is important to have the data described clearly and all data processing steps documented. Throughout this period, the safe storage of data is necessary, and it is often shared with project partners. Subsequently, the data is analyzed and interpreted, and written research outputs referring to the data sources are produced.
Once collected, data usually need to be processed before they can be analysed. This stage involves:
- Cleaning: correcting errors, removing duplicates, standardising formats.
- Validation: checking data accuracy and completeness.
- Anonymisation or pseudonymisation: removing or masking personal identifiers when required by ethical or legal constraints.
- Documentation: keeping a clear record of all changes, including the methods, scripts, or tools used.
Processing should always be carried out in a way that is transparent and reproducible. Detailed records, version control, and proper file organisation make it possible for others (and for yourself in the future) to follow and, if necessary, repeat the steps leading from raw data to results.
💡 Key message: Collecting and processing data is not just a technical step: it directly affects the reliability and credibility of your research. Careful planning, documentation, and attention to quality from the start will save time, prevent errors, and make your datasets valuable resources for long-term use and reuse.
-
✅ Checklist – Collecting and Processing Data
Do’s
-
- Plan data collection methods in advance and document them clearly.
- Keep a secure copy of raw/original data; work only on duplicates.
- Record metadata at the moment of collection (date, location, instruments, protocols).
- Calibrate instruments and check transcriptions or codings.
- Make regular backups and use version control.
- Clean, validate, and anonymise data systematically.
- Document every processing step (scripts, software, logs).
Don’ts
-
- Don’t overwrite raw data or keep only one version.
- Don’t collect more personal/sensitive data than strictly necessary.
- Don’t store files on unprotected USB sticks or personal cloud services.
- Don’t leave data undocumented — without metadata, reuse is nearly impossible.
-
-
Securing your data during the project
Research data security must be ensured throughout the entire project, regardless of the type of data involved. It’s not just about protecting sensitive or confidential files. Loss, corruption, or unauthorised access to so-called “ordinary” data can also compromise the reproducibility of your results, delay your work, or undermine the scientific reliability of your analyses.
The first step is to control access to your data. Always use a secured professional computer with a strong password, automatic session locking, and up-to-date antivirus software. Avoid storing research data on USB sticks or external hard drives that are not encrypted. Prefer using institutional storage spaces such as your lab's secured servers, research drives provided by your university, or platforms officially approved by your institution. For transferring data—especially sensitive ones—do not use email; instead, rely on secure file-sharing tools.
A regular backup strategy is also essential. A weekly, ideally automated, backup schedule can significantly reduce the risk of data loss. The recommended best practice is the “3-2-1 rule”:
- Keep 3 copies of your data
- On 2 different types of media
- With 1 copy stored off-site (e.g. on a secure remote server or trusted cloud service)
Verify your backups regularly to ensure the files are intact and readable.
Lastly, it's strongly recommended to maintain a data management logbook. This log should track where your files are stored, who can access them, what versions exist, and what significant changes have been made. A simple README.txt file in each folder can help describe its contents, creation/modification dates, and file formats. This documentation supports collaboration, workflow continuity, and future reuse—by you or others.
-
Long-Term Preservation and Archiving
Preservation and archiving aim to guarantee that research data remain accessible, understandable, and usable years—or even decades—after the end of a project. This requires anticipating technical, legal, and organisational aspects from the beginning of the research.
Why preserve research data?
Preservation is essential for scientific integrity. Data may need to be consulted again to verify results, to respond to new research questions, or to comply with funder and institutional requirements. Many institutions and funding bodies now mandate that research data be archived for a minimum period (often between 5 and 10 years after project completion, sometimes longer in clinical or environmental studies).
How to prepare for long-term archiving?
Long-term preservation of research data should be distinguished from data sharing or dissemination. While repositories are used to make selected datasets openly available, legal and institutional archiving is the responsibility of the institution, in accordance with national regulations and internal archiving policies.
- Choose sustainable formats: To facilitate long-term preservation, data should be produced and maintained in open, non-proprietary and well-documented formats (e.g. CSV, TXT, TIFF, PDF/A) rather than proprietary formats. Such formats reduce dependency on specific software and limit the risk of data loss due to technological obsolescence.
- Ensure good documentation: Preserved data must remain understandable and usable over time. This requires appropriate documentation, including metadata, README files, codebooks and, where relevant, contextual information about data collection and processing. Without this documentation, archived data rapidly lose their scientific and legal value.
- Rely on institutional archiving policies: At the end of the research activity, once no further intervention on the data is expected, a first appraisal and selection phase is carried out in collaboration with the University Archives Department of the University of Bordeaux. This applies to all research units involving the University of Bordeaux, including those with multiple supervisory institutions. The data are then organised, classified and made consistent before being transferred to an intermediate electronic archive, in line with the University’s archiving policy and regulatory obligations.
- Plan archiving from the start : Long-term archiving is easier and more robust when anticipated early in the project. Early planning helps avoid loss of contextual information, incompatible formats, or incomplete documentation, and ensures smooth interaction with institutional archival services at the end of the research.
Personal data and legal archiving
Intermediate archiving also applies to personal data. While the GDPR principle of data minimisation requires that personal data are not kept longer than necessary in active environments (workstations, online storage, cloud services), legal archiving constitutes a legitimate and mandatory purpose of data processing. Institutional archiving ensures compliance with both data protection requirements and legal obligations relating to public records and research accountability.
Archiving vs publishing
Although often used interchangeably, archiving and publishing are two distinct but complementary steps in research data management. Publishing data means making them available to others, usually through a repository, so they can be viewed, downloaded, and reused. Publishing emphasises visibility and dissemination. Data are accompanied by metadata, a persistent identifier (DOI), and often a licence specifying the conditions of reuse. Publishing may involve immediate open access, restricted access (e.g. after registration or approval), or an embargo period. The goal is to connect the data with the broader research community and increase their impact. Archiving data means ensuring their long-term preservation and integrity. Archiving focuses less on dissemination and more on durability: safeguarding files, metadata, and documentation so that they remain usable many years after the project has ended.
✅ A dataset may be archived but not published: for example, sensitive patient records preserved in a secure institutional archive, but not made openly accessible.
✅ A dataset may be published but not properly archived: for example, files uploaded on a personal website or on a non-certified platform that may disappear in a few years.
Retention periods required by institutions and funders
Most research institutions and funders impose minimum retention periods for research data. This means that even if data are not published openly, they must be preserved for a certain number of years after the project ends. The duration varies depending on the field and type of data: typically 5 to 10 years for standard research projects, but often longer in areas such as clinical trials (20+ years), environmental monitoring (long-term time series), or cultural heritage and archaeology (indefinite preservation). Institutions may also have their own archival policies for legal, financial, or scientific reasons. As a researcher, it is important to check both your university’s data policy and your funder’s requirements at the beginning of the project, and to plan accordingly.
According to the University of Bordeaux Retention and Access Schedule (RCC UBx), data archived at the institutional level are kept for a defined period (25 years by default). At the end of this period, the University Archives Department determines which data should be retained for scientific, historical or heritage value, and which may be lawfully destroyed. Researchers may provide additional retention instructions at the time of data collection.
-
Data Sharing
Why share your data?
Sharing research data is one of the key principles of Open Science. Well-structured and documented datasets have value beyond the original project: they can be reused, combined with other data, or serve as a basis for new discoveries.
The main reasons for sharing data are:
- Scientific transparency and trust: Openly available data allow others to verify methods, reproduce results, and strengthen confidence in scientific outcomes.
- Efficiency and reuse: By making data accessible, duplication of costly or time-consuming data collection is avoided. Other researchers can reuse your data for comparative studies, meta-analyses, or educational purposes.
- Visibility and recognition: Datasets that are published in repositories with persistent identifiers (DOIs) can be cited, giving credit to the data creators. This increases the impact of your work and your visibility as a researcher.
- Collaboration and innovation: Shared data can be combined across disciplines or countries, leading to new partnerships and broader research questions.
- Compliance with funder requirements: Most research funders, including the European Commission, now mandate that data be made “as open as possible, as closed as necessary,” unless legal, ethical, or contractual restrictions apply.
In short, sharing your data is not an additional burden but a way of maximising the scientific, educational, and societal value of your work.
Examples of potential reuse of the data beyond your project
-
-
- A RNA-Seq dataset deposited in GEO might be reused in an international meta-analysis on immune responses across diseases.
- A set of annotated archaeological photographs could help train a computer vision model to recognise ancient artefacts.
- An anonymised and coded interview corpus in the social sciences might be reused to study similar topics in another region or cultural context.
- Experimental data from materials science could be reused in Master’s-level lab courses for training in interpreting spectra or diffraction curves.
- Python scripts or models shared on GitHub and archived on Software Heritage can be adapted by other PhD students working on different datasets.
-
💡 Key takeaway: From the very beginning of your project, think about what your data could offer beyond your own research — to other researchers, educators, professionals, or society at large. Include this “future use” perspective in each dataset description, specifying what your data could enable, in which context, and under what conditions.
📂 What data should be shared?
Not all data generated during a research project need to be shared. The goal is to make available those datasets that are necessary to understand, validate, and reuse the results of your work. Sharing should be selective and thoughtful, based on scientific relevance as well as legal and ethical considerations.
✅ What to share:
- Data underlying publications: the essential datasets that support the figures, tables, or conclusions in your thesis or articles.
- Processed and cleaned versions: data that have been curated and documented to be understandable by others (not necessarily all raw data, which may be too large, messy, or sensitive).
- Representative samples of very large datasets, together with the method for generating them.
- Code, scripts, and workflows used to analyse or process the data, so that results can be reproduced.
- Metadata and documentation that explain how the data were collected, structured, and processed.
✅ What may not be shared:
- Sensitive personal data that cannot be anonymised without compromising their scientific value.
- Confidential or restricted data (e.g. from industrial partners, security-related research, endangered species, or cultural heritage with access limitations).
- Redundant or low-value data (e.g. temporary files, intermediate outputs that are not needed for reproducibility).
❗The guiding principle is: “as open as possible, as closed as necessary.” Even when data cannot be openly shared, you should still provide metadata describing their existence, conditions of access, and reasons for restriction.
🕒 When should data be shared?
The timing of data sharing is just as important as deciding what to share. Ideally, research data should be made available at the point where they can have the greatest impact, while also respecting the constraints of the project, funder, and ethical/legal requirements.
Typical moments for sharing:
- At the time of publication: Datasets underlying a journal article, conference paper, or thesis chapter should be deposited in a trusted repository and linked to the publication. This ensures transparency and allows readers to access and reuse the data immediately.
- At the end of a project: Many funders require that research data be deposited once the project is completed. This ensures preservation and reuse, even beyond the life of the project.
- During the project (when appropriate): Some datasets may have value for the community even before final results are published. Sharing early can foster collaborations and accelerate discovery, but researchers must balance this with the need to protect intellectual contributions and ongoing work.
Special cases:
- Embargo periods may be applied when data cannot be shared immediately (e.g. to allow for publication or patenting). In such cases, metadata should still be made available, with a clear indication of when the data will be released.
- Restricted access may be necessary for sensitive or confidential datasets. Even then, metadata describing the dataset and its access conditions should be deposited.
💡 Key principle: data should be shared as soon as they are ready to be understood and reused by others—not necessarily raw or unfinished versions, but curated datasets that support transparency and reproducibility.
📚 What are data papers and data journals?
A data paper is a peer-reviewed document describing a dataset published in a peer-reviewed journal. Data papers provide recognition for the effort to e.g. prepare, curate, and describe data by means of a scholarly article. The primary purpose of a data paper is to describe data and the circumstances of their collection, rather than to report hypotheses and conclusions.
Data journals consist of data articles that describe how, why and when a dataset was collected and how any derived data product produced. Data journals provide strong incentives for data creators to verify, document and disseminate their data. They also bring data access and documentation into the mainstream of scholarly communication, rewarding data creators through existing mechanisms of peer-reviewed publication and citation tracking.
-
✅ [Checklist] Why share your data?
- Does sharing my data make my research more transparent?
- Could my dataset be useful for others (e.g. comparisons, teaching, meta-analyses)?
- Will sharing improve my visibility and citations?
- Does my funder or institution require data sharing?
- Have I thought about the long-term value of my dataset beyond my thesis or project?
-
✅ [Checklist] What to share?
- Does this dataset support my publications or thesis results?
- Is it well-documented enough to be understood and reused?
- Have I removed or anonymised sensitive information?
- Am I respecting confidentiality agreements or legal restrictions?
- If I cannot share the data, have I at least shared the metadata and explained the restrictions?
-
Taking into account non-digital research outputs
Data management does not concern only digital files. In many research fields, physical objects or analogue materials play a central role in scientific production. Laboratory notebooks, field journals, annotated sketches, excavation plans, biological or geological samples, artefacts, prototypes or models created during the project, as well as older analogue media such as magnetic tapes, films or photographic prints, must all be considered in the Data Management Plan. This is important for reasons of traceability, archiving, or scientific value.
Even if these objects are not always intended to be digitised or disseminated online, they nonetheless contribute to the construction of research results. They may justify or document an observation, serve as a reference, or be reused in secondary ways such as illustration, reconstruction, comparison, or exhibition. Their preservation therefore requires specific attention. It is important to inventory and describe them, to plan storage conditions, and to clarify their legal or ethical status, particularly when they were collected in the field or come from regulated contexts.
In a DMP, these objects should be described as precisely as possible: their nature, number, context of collection or creation, ownership status, and any possible connections with associated digital datasets. It is recommended to keep an inventory register, either on paper or in digital form, mentioning for each item the date, place, responsible person, storage conditions, and any restrictions on access or dissemination. When partial digitisation is possible, for example through high-resolution photographs or annotated scans, this can facilitate documentation, sharing, and the illustration of research results.
Finally, some objects may be subject to specific obligations at the end of the project, such as restitution to an administrative authority, deposit in a heritage collection, or controlled destruction. It is therefore essential to anticipate, from the project’s design stage, the conditions of transfer, the necessary authorisations, and the institutional contacts to involve if required.
-
[Example] Description sheet for non-digital research data
-
Egon Heuson. ouvrirlascience. Data management and the life cycle of research data , in Passport for Open Science. [Vidéo]. Canal-U. https://www.canal-u.tv/138448.
-
Self-Assessment Quiz
-
[Self-assessment quiz] Research Data Lifecycle and RDM